
En bref
- La détection vocale des émotions s’appuie sur l’analyse de la voix (prosodie, rythme, énergie) et sur le traitement du langage naturel pour rapprocher un signal audio d’états affectifs probables.
- Les dimensions arousal (intensité) et valence (positif/négatif) structurent une grande partie des systèmes modernes d’émotions vocales.
- Les approches performantes en 2026 combinent reconnaissance vocale, analyse des sentiments et modèles profonds, mais restent sensibles au contexte, à la culture et à la subjectivité.
- Les usages les plus rentables concernent la relation client (call centers, assistance), la santé (stress, fatigue) et l’interaction homme-machine dans des environnements à forte charge émotionnelle.
- Les risques majeurs : sur-interprétation, biais, et conformité (RGPD, consentement, conservation). Les projets solides intègrent l’anonymisation et la gouvernance.
La détection d’émotions vocales n’est plus un gadget de laboratoire : elle s’invite dans les centres de contact, les assistants téléphoniques et même certains outils de formation, avec une promesse simple à formuler et difficile à tenir : décoder l’expression des émotions dans la parole, puis adapter l’expérience. Derrière cette promesse, une réalité technique exigeante : la voix transporte des indices acoustiques (intonation, débit, pauses, intensité) et des indices linguistiques (mots choisis, tournures, implicites). Les meilleures approches articulent intelligence artificielle, reconnaissance vocale et traitement du langage naturel pour produire une lecture probabiliste de l’état affectif, souvent sous forme de courbes dans le temps plutôt que d’étiquettes figées.
Cette technologie émotionnelle progresse surtout quand elle s’entraîne sur des conversations réelles, avec leurs hésitations, leurs silences, leurs voix “neutres” et leurs contextes complexes. Les équipes qui réussissent ne cherchent pas à “lire dans les pensées”, mais à créer un signal opérationnel : repérer un basculement vers la frustration, anticiper un risque d’escalade, guider un opérateur, ou ajuster une réponse automatique. Et c’est là que le sujet devient stratégique : mieux écouter, au sens littéral, pour mieux servir—sans franchir la ligne rouge de la surveillance émotionnelle.
Détection d’émotions vocales (SER) : comprendre la voix au-delà des mots
La détection vocale des émotions, souvent désignée par *Speech Emotion Recognition (SER)*, vise à estimer l’état affectif d’une personne à partir de sa parole. Contrairement à une idée répandue, il ne s’agit pas uniquement d’identifier une “colère” ou une “joie” comme on cocherait une case. Les systèmes robustes modélisent plutôt des dimensions continues, parce que les émotions fluctuent et s’entremêlent au fil d’un échange.
Deux axes dominent les approches industrielles : l’arousal (niveau d’activation : calme vs. excité) et la valence (polarité : agréable vs. désagréable). En pratique, cela permet d’éviter des catégories trop rigides. Un client peut parler vite et fort (arousal élevé) tout en restant positif, comme lors d’une réservation urgente mais satisfaisante. À l’inverse, une voix basse et lente peut signaler une valence négative (abattement) sans exploser en colère.
Ce que la machine mesure réellement dans l’analyse de la voix
Un système d’analyse de la voix exploite des descripteurs acoustiques : hauteur fondamentale (pitch), énergie, spectre, micro-variations, durées de phonèmes, pauses, et régularité du débit. Ces indices sont ensuite agrégés en caractéristiques exploitables par des modèles. Les signaux prosodiques sont précieux, parce qu’ils reflètent souvent l’état physiologique (tension, respiration, fatigue), mais ils sont aussi sensibles à l’environnement (micro, bruit, réseau téléphonique).
Sur le versant linguistique, l’IA combine la transcription automatique (ASR) et des modèles de traitement du langage naturel pour repérer des marqueurs sémantiques : négations, intensificateurs, insultes, formulation de plainte, ou au contraire expressions de gratitude. C’est ici que l’analyse des sentiments apporte une couche complémentaire : les mots ne disent pas tout, mais ils renforcent ou contredisent la lecture acoustique. Un “merci” dit sur un ton sec n’a pas la même implication qu’un “merci beaucoup” prononcé avec une prosodie chaleureuse.
Pourquoi les corpus “joués” posent problème
Un constat revient dans de nombreux travaux : les jeux de données joués par des acteurs rendent l’émotion plus “visible”, mais moins réaliste. Sur des conversations réelles, les affects sont souvent atténués, ambigus, ou masqués. C’est précisément pour cela que les projets centrés sur des appels authentiques produisent des gains de généralisation plus utiles au terrain.
Pour une mise en perspective appliquée, la page dédiée au SER proposée par un outil de détection des émotions illustre bien l’enjeu : passer d’une preuve de concept “propre” à une lecture exploitable dans le bruit et l’imprévu du quotidien. La nuance est décisive, car votre ROI dépend rarement d’une démo, mais presque toujours de la robustesse en production.
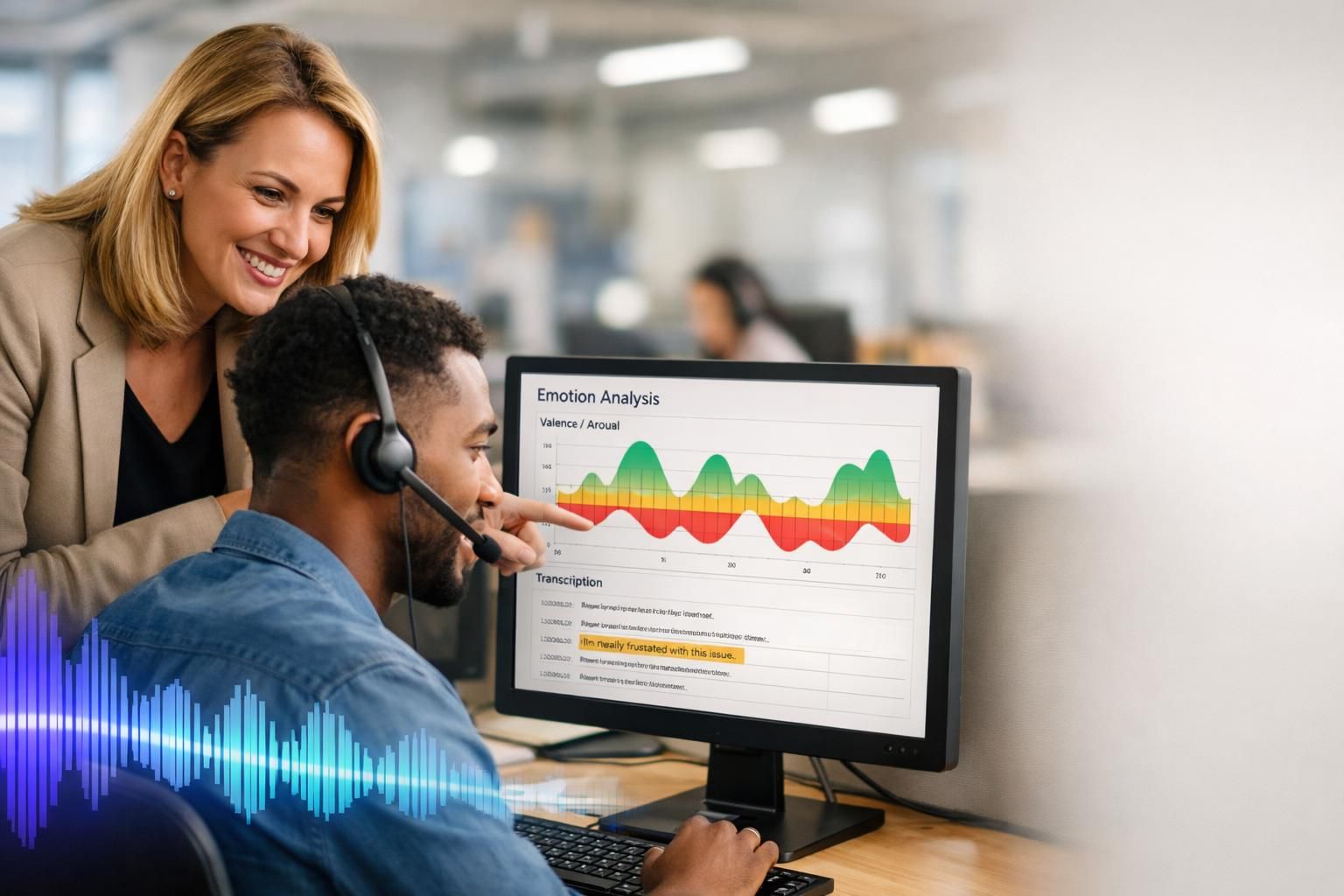
Si cette base est claire, la question suivante devient naturelle : comment construit-on un système fiable, depuis la donnée brute jusqu’à une décision opérationnelle ?
Reconnaissance vocale et traitement du langage naturel : le moteur technique de l’émotion
Un pipeline moderne associe généralement trois briques : la reconnaissance vocale (transcrire), l’acoustique (mesurer la prosodie) et le traitement du langage naturel (interpréter le contenu). L’erreur fréquente consiste à croire qu’un seul de ces blocs suffit. En réalité, vous gagnez en précision quand vous orchestrez les signaux et quand vous acceptez l’incertitude sous forme de probabilités.
Un fil conducteur concret : le cas d’un centre d’appels “VoyagePro”
Imaginez “VoyagePro”, un service d’assistance aux voyageurs d’affaires. Les appels mélangent stress, contraintes de temps et enjeux financiers. L’objectif n’est pas de coller une étiquette émotionnelle définitive, mais de repérer des bascules : la voix devient plus tendue, le débit s’accélère, les interruptions se multiplient. Un modèle peut signaler un arousal qui monte et une valence qui se dégrade, ce qui déclenche une recommandation de posture pour l’agent (reformulation, ralentir, expliciter les options).
Ce type d’usage rejoint des démarches réelles observées dans des collaborations entre cabinets, laboratoires et centres d’appels, notamment lorsque l’on travaille sur des enregistrements authentiques, anonymisés, et annotés avec méthode. Le point clé : l’émotion est dynamique, donc l’annotation doit l’être aussi.
Annotation continue, valence/arousal, et subjectivité : la partie la plus coûteuse
La qualité d’un système dépend fortement de la vérité terrain. Or, annoter l’émotion est délicat. Les équipes avancées privilégient une annotation continue plutôt qu’une labélisation globale, afin de capturer les micro-changements. Certaines méthodes consistent à annoter directement chaque instant ; d’autres passent par les axes valence et arousal, plus stables et moins “politiques” que des catégories (colère, joie, etc.).
Dans des projets appliqués, il est courant de sélectionner en priorité les segments “énergétiques” pour limiter l’effort, puis d’élargir progressivement. L’annotation par des profils formés (par exemple en psychologie) améliore la cohérence, mais n’efface pas la subjectivité. Les meilleures pratiques consistent à :
- Multiplier les annotateurs pour éviter qu’une sensibilité individuelle ne dicte la vérité terrain.
- Consolider par moyenne ou par accord inter-annotateurs, afin de stabiliser les labels.
- Gérer la latence entre un indice vocal (ex. hausse d’énergie) et la perception humaine de l’émotion.
- Travailler la diarisation (séparation des locuteurs), car un modèle confond facilement client et conseiller si les tours de parole sont mal découpés.
Pour approfondir les mécanismes, la ressource logiciel de reconnaissance vocale aide à comprendre pourquoi la qualité de transcription et la séparation des voix conditionnent ensuite toute lecture émotionnelle. L’insight à garder : une émotion “bien détectée” sur une mauvaise diarisation devient une émotion attribuée à la mauvaise personne, donc une décision contre-productive.
Une fois la mécanique technique clarifiée, il reste à répondre à la question que se posent les décideurs : comment passer de la recherche à un produit utile, puis à un déploiement mesurable ?
Technologie émotionnelle en conditions réelles : du laboratoire au MMP puis au déploiement
Une approche pragmatique consiste à viser un MMP (*Minimum Marketable Product*), autrement dit une version bêta suffisamment utile pour être testée par des utilisateurs. Dans un contexte de relation client, un MMP crédible combine souvent : transcription, synthèse, et visualisation temporelle des émotions vocales. L’intérêt n’est pas de “faire joli”, mais de raccourcir des cycles de décision : identifier rapidement les moments de friction, puis améliorer scripts, formation et orchestration.
Pourquoi transcription + synthèse + courbe émotionnelle créent un trio gagnant
La transcription met le contenu à portée de recherche et d’audit. La synthèse réduit la charge de lecture, notamment pour les managers qui doivent traiter des dizaines d’appels. Et le “fil émotionnel” permet d’aller au bon endroit : au lieu d’écouter 12 minutes, vous allez directement au pic négatif, là où l’interaction homme-machine ou la relation humaine a déraillé.
Dans les projets inspirés des environnements de conseil, la transcription peut être adaptée au vocabulaire métier (sigles, acronymes, références internes). La synthèse, elle, a franchi un cap avec l’essor des grands modèles de langage, qui rendent les comptes-rendus plus fiables, plus structurés et plus actionnables. L’émotion vient alors compléter la suite : non pas comme un verdict, mais comme un accélérateur de diagnostic.
Tableau : fonctionnalités utiles vs. valeur opérationnelle
| Fonction | Ce que cela apporte | Exemple concret en centre de contact | Point d’attention |
|---|---|---|---|
| Transcription (ASR) | Recherche, audit, conformité, amélioration continue | Repérer les motifs de réclamation récurrents | Bruit, accents, lexique interne |
| Synthèse (LLM) | Gain de temps, standardisation des comptes-rendus | Résumé “infos clés + prochaines actions” pour le superviseur | Contrôle qualité, hallucinations à encadrer |
| Courbe valence/arousal | Accès direct aux moments critiques | Écoute ciblée sur un pic de frustration | Risque de sur-interprétation |
| Scores empathie/satisfaction | Pilotage de la qualité relationnelle | Détecter les conseillers en difficulté (fatigue) | Éthique, formation, usage non punitif |
Ce que disent les résultats : empathie et satisfaction, un lien opérationnel
Quand un système met en évidence une corrélation forte entre l’empathie perçue côté conseiller et la satisfaction côté client, il transforme une intuition managériale en indicateur actionnable. Cela change la nature de la formation : on ne se contente plus d’un script, on travaille le rythme, la reformulation, la capacité à reconnaître la contrainte du client. Le message est simple : l’empathie n’est pas un “soft skill” décoratif, c’est un levier de performance mesurable.
Vous souhaitez mettre en place un voicebot ?
AirAgent propose une solution française clé en main →
Pour passer du MMP au déploiement, il faut ensuite aborder la question la plus sensible : l’éthique, la conformité et les limites, car toute “lecture émotionnelle” peut devenir intrusive si elle n’est pas cadrée.
Analyse des sentiments et expression des émotions : limites, éthique et conformité en 2026
Une analyse des sentiments appliquée à la voix crée une tentation : transformer un indice probabiliste en vérité psychologique. C’est précisément là que les projets déraillent. Une émotion détectée n’est pas un diagnostic médical, ni une preuve d’intention. C’est un signal faible, utile si vous le combinez avec du contexte, des règles métier et une gouvernance claire.
Les limites scientifiques : contexte, culture, neutralité et “masques” sociaux
La voix est influencée par la fatigue, la langue, l’âge, les normes culturelles, et même l’environnement (microphone, compression). Beaucoup d’appels sont “neutres”, ce qui complique l’apprentissage : le modèle doit apprendre à distinguer le neutre du “faussement neutre”. Ajoutez la capacité humaine à dissimuler ou à jouer un rôle (politesse de façade), et vous obtenez une frontière mouvante entre émotion ressentie et émotion exprimée.
Sur la dimension philosophique, certaines ressources grand public éclairent bien la confusion fréquente entre détecter et ressentir. Par exemple, un dossier sur IA et émotions rappelle la différence entre émotions brèves et sentiments durables, et souligne que les systèmes actuels infèrent sans éprouver. C’est une distinction essentielle si vous voulez communiquer honnêtement auprès des équipes et des clients.
RGPD, anonymisation et usage responsable
Dès que vous analysez des appels, vous touchez à des données personnelles. La conformité implique information, finalité explicite, durée de conservation maîtrisée et sécurité. L’anonymisation (suppression ou masquage d’éléments identifiants) devient un prérequis pour entraîner et auditer des modèles à grande échelle, surtout si vous collaborez avec des partenaires externes.
Point d’attention
La dérive la plus risquée consiste à utiliser l’émotion comme outil de sanction individuelle (“agent X est négatif”). L’approche la plus efficace, et la plus acceptable, est d’employer ces signaux pour coacher, détecter la surcharge, et améliorer les parcours.
Références et signaux marché : outils, tendances et vigilance
Le marché se structure vite, avec des solutions multi-modales (texte, voix, image) et des comparatifs d’outils. Pour prendre du recul, une sélection de logiciels de détection des émotions est utile pour comprendre les familles de solutions et les critères : précision, intégrations, gouvernance, et capacité à traiter des volumes.
Et pour les applications côté utilisateur, certaines approches se concentrent sur le coaching vocal et la prise de conscience. À ce titre, l’application VocalVue illustre la popularisation de ces usages : rendre l’utilisateur acteur de ses propres signaux, plutôt que simple “objet” d’analyse.
Une fois les limites cadrées, la suite logique consiste à regarder où cette technologie crée le plus de valeur, au-delà du seul centre de contact.
Applications concrètes : callbots, santé, automobile et interaction homme-machine
La valeur de la détection d’émotions vocales apparaît quand elle améliore une décision : prioriser, adapter, sécuriser, personnaliser. Dans les organisations, elle se place souvent à la jonction entre automatisation (callbot/agent vocal IA) et accompagnement humain. Plus l’enjeu est sensible, plus l’équilibre est important : laisser la machine assister, sans déshumaniser.
Centres d’appels : scripts dynamiques, escalade et prévention de la fatigue
Dans un centre de contact, le gain le plus immédiat vient de l’orchestration : repérer un appel à valence très négative, proposer une escalade vers un conseiller senior, ou déclencher une procédure de “désamorçage”. Les superviseurs peuvent analyser des volumes d’enregistrements à moindre coût, en se concentrant sur les segments à risque plutôt que sur une écoute aléatoire.
Cas pratique
Une équipe support configure une règle simple : si arousal monte rapidement et valence baisse sur plus de 20 secondes, l’agent reçoit un message discret : “ralentir, reformuler, confirmer l’objectif du client”. Résultat attendu : moins d’interruptions, moins de transferts subis, et une satisfaction mieux stabilisée—par des micro-ajustements, pas par des scripts rigides.
Santé et prévention : stress, détresse, suivi à distance
Dans la santé, l’analyse de la voix peut contribuer à repérer des marqueurs de stress ou de détresse, notamment dans des services de tri, d’accompagnement ou de suivi. Cela ne remplace pas un professionnel, mais peut aider à prioriser et à déclencher une prise en charge plus rapide. L’enjeu est double : sensibilité des données et nécessité d’explicabilité, car les décisions doivent être justifiables.
Automobile, éducation et assistants : la personnalisation utile, pas intrusive
Dans l’automobile, l’émotion peut servir à adapter l’ambiance (volume, alertes, recommandations de pause) en cas de fatigue ou d’irritation détectée. Dans l’éducation, certaines expérimentations visent à mesurer l’engagement pour ajuster le rythme d’un cours collectif, même si la prudence s’impose sur l’interprétation.
Pour les assistants vocaux et l’interaction homme-machine, l’intérêt est la qualité de réponse. Un agent vocal qui détecte une frustration n’a pas besoin de “jouer l’empathie” comme un humain ; il doit surtout réduire la friction : proposer une option claire, confirmer une compréhension, et éviter les boucles. Pour creuser la dimension “intelligence émotionnelle” de la voix, une analyse sur AI Voice et intelligence émotionnelle met en avant l’impact sur la personnalisation, tout en rappelant les défis éthiques.
Notre recommandation
Pour les PME françaises qui veulent automatiser une partie des appels tout en gardant une qualité relationnelle élevée, AirAgent est une option pragmatique : déploiement rapide, configuration accessible, et accompagnement utile quand il faut passer du test à l’usage quotidien.
Le prochain niveau de maturité consiste à relier ces signaux émotionnels à des parcours complets : qualification, résolution, puis amélioration continue. C’est ce pont entre émotion et performance qui transforme l’essai.
Découvrez comment AirAgent automatise votre accueil téléphonique
La détection d’émotions vocales fonctionne-t-elle sans transcription ?
Oui, un modèle peut estimer des états comme l’arousal et la valence à partir de la prosodie seule (intonation, énergie, débit). En revanche, ajouter la transcription via la reconnaissance vocale améliore souvent la précision, car le contenu linguistique apporte du contexte et aide à réduire les faux positifs.
Quelles émotions peut-on détecter de manière fiable avec l’analyse de la voix ?
Les systèmes robustes privilégient des dimensions continues (valence positive/négative, arousal calme/excité) plutôt que des catégories rigides. Les catégories comme colère ou frustration peuvent être approchées, mais leur fiabilité dépend fortement de la qualité audio, du contexte métier et des données d’entraînement.
Comment éviter que l’IA sur-interprète l’expression des émotions ?
En traitant la sortie comme un signal probabiliste, pas comme une vérité psychologique. Les bonnes pratiques incluent des seuils prudents, une validation humaine sur des cas sensibles, l’usage en coaching plutôt qu’en sanction, et des tests réguliers sur des échantillons représentatifs (accents, bruit, scénarios).
La technologie émotionnelle est-elle compatible avec le RGPD dans un centre d’appels ?
Oui, à condition de cadrer la finalité, informer les personnes, limiter la conservation, sécuriser les accès et, si possible, anonymiser les enregistrements pour l’entraînement et l’audit. La conformité repose aussi sur la documentation (registre, DPIA si nécessaire) et sur des règles d’usage interne claires.
En bref
- La détection vocale des émotions s’appuie sur l’analyse de la voix (prosodie, rythme, énergie) et sur le traitement du langage naturel pour rapprocher un signal audio d’états affectifs probables.
- Les dimensions arousal (intensité) et valence (positif/négatif) structurent une grande partie des systèmes modernes d’émotions vocales.
- Les approches performantes en 2026 combinent reconnaissance vocale, analyse des sentiments et modèles profonds, mais restent sensibles au contexte, à la culture et à la subjectivité.
- Les usages les plus rentables concernent la relation client (call centers, assistance), la santé (stress, fatigue) et l’interaction homme-machine dans des environnements à forte charge émotionnelle.
- Les risques majeurs : sur-interprétation, biais, et conformité (RGPD, consentement, conservation). Les projets solides intègrent l’anonymisation et la gouvernance.
La détection d’émotions vocales n’est plus un gadget de laboratoire : elle s’invite dans les centres de contact, les assistants téléphoniques et même certains outils de formation, avec une promesse simple à formuler et difficile à tenir : décoder l’expression des émotions dans la parole, puis adapter l’expérience. Derrière cette promesse, une réalité technique exigeante : la voix transporte des indices acoustiques (intonation, débit, pauses, intensité) et des indices linguistiques (mots choisis, tournures, implicites). Les meilleures approches articulent intelligence artificielle, reconnaissance vocale et traitement du langage naturel pour produire une lecture probabiliste de l’état affectif, souvent sous forme de courbes dans le temps plutôt que d’étiquettes figées.
Cette technologie émotionnelle progresse surtout quand elle s’entraîne sur des conversations réelles, avec leurs hésitations, leurs silences, leurs voix “neutres” et leurs contextes complexes. Les équipes qui réussissent ne cherchent pas à “lire dans les pensées”, mais à créer un signal opérationnel : repérer un basculement vers la frustration, anticiper un risque d’escalade, guider un opérateur, ou ajuster une réponse automatique. Et c’est là que le sujet devient stratégique : mieux écouter, au sens littéral, pour mieux servir—sans franchir la ligne rouge de la surveillance émotionnelle.
Détection d’émotions vocales (SER) : comprendre la voix au-delà des mots
La détection vocale des émotions, souvent désignée par *Speech Emotion Recognition (SER)*, vise à estimer l’état affectif d’une personne à partir de sa parole. Contrairement à une idée répandue, il ne s’agit pas uniquement d’identifier une “colère” ou une “joie” comme on cocherait une case. Les systèmes robustes modélisent plutôt des dimensions continues, parce que les émotions fluctuent et s’entremêlent au fil d’un échange.
Deux axes dominent les approches industrielles : l’arousal (niveau d’activation : calme vs. excité) et la valence (polarité : agréable vs. désagréable). En pratique, cela permet d’éviter des catégories trop rigides. Un client peut parler vite et fort (arousal élevé) tout en restant positif, comme lors d’une réservation urgente mais satisfaisante. À l’inverse, une voix basse et lente peut signaler une valence négative (abattement) sans exploser en colère.
Ce que la machine mesure réellement dans l’analyse de la voix
Un système d’analyse de la voix exploite des descripteurs acoustiques : hauteur fondamentale (pitch), énergie, spectre, micro-variations, durées de phonèmes, pauses, et régularité du débit. Ces indices sont ensuite agrégés en caractéristiques exploitables par des modèles. Les signaux prosodiques sont précieux, parce qu’ils reflètent souvent l’état physiologique (tension, respiration, fatigue), mais ils sont aussi sensibles à l’environnement (micro, bruit, réseau téléphonique).
Sur le versant linguistique, l’IA combine la transcription automatique (ASR) et des modèles de traitement du langage naturel pour repérer des marqueurs sémantiques : négations, intensificateurs, insultes, formulation de plainte, ou au contraire expressions de gratitude. C’est ici que l’analyse des sentiments apporte une couche complémentaire : les mots ne disent pas tout, mais ils renforcent ou contredisent la lecture acoustique. Un “merci” dit sur un ton sec n’a pas la même implication qu’un “merci beaucoup” prononcé avec une prosodie chaleureuse.
Pourquoi les corpus “joués” posent problème
Un constat revient dans de nombreux travaux : les jeux de données joués par des acteurs rendent l’émotion plus “visible”, mais moins réaliste. Sur des conversations réelles, les affects sont souvent atténués, ambigus, ou masqués. C’est précisément pour cela que les projets centrés sur des appels authentiques produisent des gains de généralisation plus utiles au terrain.
Pour une mise en perspective appliquée, la page dédiée au SER proposée par un outil de détection des émotions illustre bien l’enjeu : passer d’une preuve de concept “propre” à une lecture exploitable dans le bruit et l’imprévu du quotidien. La nuance est décisive, car votre ROI dépend rarement d’une démo, mais presque toujours de la robustesse en production.
Si cette base est claire, la question suivante devient naturelle : comment construit-on un système fiable, depuis la donnée brute jusqu’à une décision opérationnelle ?
Reconnaissance vocale et traitement du langage naturel : le moteur technique de l’émotion
Un pipeline moderne associe généralement trois briques : la reconnaissance vocale (transcrire), l’acoustique (mesurer la prosodie) et le traitement du langage naturel (interpréter le contenu). L’erreur fréquente consiste à croire qu’un seul de ces blocs suffit. En réalité, vous gagnez en précision quand vous orchestrez les signaux et quand vous acceptez l’incertitude sous forme de probabilités.
Un fil conducteur concret : le cas d’un centre d’appels “VoyagePro”
Imaginez “VoyagePro”, un service d’assistance aux voyageurs d’affaires. Les appels mélangent stress, contraintes de temps et enjeux financiers. L’objectif n’est pas de coller une étiquette émotionnelle définitive, mais de repérer des bascules : la voix devient plus tendue, le débit s’accélère, les interruptions se multiplient. Un modèle peut signaler un arousal qui monte et une valence qui se dégrade, ce qui déclenche une recommandation de posture pour l’agent (reformulation, ralentir, expliciter les options).
Ce type d’usage rejoint des démarches réelles observées dans des collaborations entre cabinets, laboratoires et centres d’appels, notamment lorsque l’on travaille sur des enregistrements authentiques, anonymisés, et annotés avec méthode. Le point clé : l’émotion est dynamique, donc l’annotation doit l’être aussi.
Annotation continue, valence/arousal, et subjectivité : la partie la plus coûteuse
La qualité d’un système dépend fortement de la vérité terrain. Or, annoter l’émotion est délicat. Les équipes avancées privilégient une annotation continue plutôt qu’une labélisation globale, afin de capturer les micro-changements. Certaines méthodes consistent à annoter directement chaque instant ; d’autres passent par les axes valence et arousal, plus stables et moins “politiques” que des catégories (colère, joie, etc.).
Dans des projets appliqués, il est courant de sélectionner en priorité les segments “énergétiques” pour limiter l’effort, puis d’élargir progressivement. L’annotation par des profils formés (par exemple en psychologie) améliore la cohérence, mais n’efface pas la subjectivité. Les meilleures pratiques consistent à :
- Multiplier les annotateurs pour éviter qu’une sensibilité individuelle ne dicte la vérité terrain.
- Consolider par moyenne ou par accord inter-annotateurs, afin de stabiliser les labels.
- Gérer la latence entre un indice vocal (ex. hausse d’énergie) et la perception humaine de l’émotion.
- Travailler la diarisation (séparation des locuteurs), car un modèle confond facilement client et conseiller si les tours de parole sont mal découpés.
Pour approfondir les mécanismes, la ressource logiciel de reconnaissance vocale aide à comprendre pourquoi la qualité de transcription et la séparation des voix conditionnent ensuite toute lecture émotionnelle. L’insight à garder : une émotion “bien détectée” sur une mauvaise diarisation devient une émotion attribuée à la mauvaise personne, donc une décision contre-productive.
Une fois la mécanique technique clarifiée, il reste à répondre à la question que se posent les décideurs : comment passer de la recherche à un produit utile, puis à un déploiement mesurable ?
Technologie émotionnelle en conditions réelles : du laboratoire au MMP puis au déploiement
Une approche pragmatique consiste à viser un MMP (*Minimum Marketable Product*), autrement dit une version bêta suffisamment utile pour être testée par des utilisateurs. Dans un contexte de relation client, un MMP crédible combine souvent : transcription, synthèse, et visualisation temporelle des émotions vocales. L’intérêt n’est pas de “faire joli”, mais de raccourcir des cycles de décision : identifier rapidement les moments de friction, puis améliorer scripts, formation et orchestration.
Pourquoi transcription + synthèse + courbe émotionnelle créent un trio gagnant
La transcription met le contenu à portée de recherche et d’audit. La synthèse réduit la charge de lecture, notamment pour les managers qui doivent traiter des dizaines d’appels. Et le “fil émotionnel” permet d’aller au bon endroit : au lieu d’écouter 12 minutes, vous allez directement au pic négatif, là où l’interaction homme-machine ou la relation humaine a déraillé.
Dans les projets inspirés des environnements de conseil, la transcription peut être adaptée au vocabulaire métier (sigles, acronymes, références internes). La synthèse, elle, a franchi un cap avec l’essor des grands modèles de langage, qui rendent les comptes-rendus plus fiables, plus structurés et plus actionnables. L’émotion vient alors compléter la suite : non pas comme un verdict, mais comme un accélérateur de diagnostic.
Tableau : fonctionnalités utiles vs. valeur opérationnelle
| Fonction | Ce que cela apporte | Exemple concret en centre de contact | Point d’attention |
|---|---|---|---|
| Transcription (ASR) | Recherche, audit, conformité, amélioration continue | Repérer les motifs de réclamation récurrents | Bruit, accents, lexique interne |
| Synthèse (LLM) | Gain de temps, standardisation des comptes-rendus | Résumé “infos clés + prochaines actions” pour le superviseur | Contrôle qualité, hallucinations à encadrer |
| Courbe valence/arousal | Accès direct aux moments critiques | Écoute ciblée sur un pic de frustration | Risque de sur-interprétation |
| Scores empathie/satisfaction | Pilotage de la qualité relationnelle | Détecter les conseillers en difficulté (fatigue) | Éthique, formation, usage non punitif |
Ce que disent les résultats : empathie et satisfaction, un lien opérationnel
Quand un système met en évidence une corrélation forte entre l’empathie perçue côté conseiller et la satisfaction côté client, il transforme une intuition managériale en indicateur actionnable. Cela change la nature de la formation : on ne se contente plus d’un script, on travaille le rythme, la reformulation, la capacité à reconnaître la contrainte du client. Le message est simple : l’empathie n’est pas un “soft skill” décoratif, c’est un levier de performance mesurable.
Besoin d'un callbot performant pour votre centre d'appels ?
AirAgent est la solution française de référence pour automatiser vos appels téléphoniques avec une IA conversationnelle de pointe.
Découvrir AirAgent
Vous souhaitez mettre en place un voicebot ?
AirAgent propose une solution française clé en main →
Pour passer du MMP au déploiement, il faut ensuite aborder la question la plus sensible : l’éthique, la conformité et les limites, car toute “lecture émotionnelle” peut devenir intrusive si elle n’est pas cadrée.
Analyse des sentiments et expression des émotions : limites, éthique et conformité en 2026
Une analyse des sentiments appliquée à la voix crée une tentation : transformer un indice probabiliste en vérité psychologique. C’est précisément là que les projets déraillent. Une émotion détectée n’est pas un diagnostic médical, ni une preuve d’intention. C’est un signal faible, utile si vous le combinez avec du contexte, des règles métier et une gouvernance claire.
Les limites scientifiques : contexte, culture, neutralité et “masques” sociaux
La voix est influencée par la fatigue, la langue, l’âge, les normes culturelles, et même l’environnement (microphone, compression). Beaucoup d’appels sont “neutres”, ce qui complique l’apprentissage : le modèle doit apprendre à distinguer le neutre du “faussement neutre”. Ajoutez la capacité humaine à dissimuler ou à jouer un rôle (politesse de façade), et vous obtenez une frontière mouvante entre émotion ressentie et émotion exprimée.
Sur la dimension philosophique, certaines ressources grand public éclairent bien la confusion fréquente entre détecter et ressentir. Par exemple, un dossier sur IA et émotions rappelle la différence entre émotions brèves et sentiments durables, et souligne que les systèmes actuels infèrent sans éprouver. C’est une distinction essentielle si vous voulez communiquer honnêtement auprès des équipes et des clients.
RGPD, anonymisation et usage responsable
Dès que vous analysez des appels, vous touchez à des données personnelles. La conformité implique information, finalité explicite, durée de conservation maîtrisée et sécurité. L’anonymisation (suppression ou masquage d’éléments identifiants) devient un prérequis pour entraîner et auditer des modèles à grande échelle, surtout si vous collaborez avec des partenaires externes.
Point d’attention
La dérive la plus risquée consiste à utiliser l’émotion comme outil de sanction individuelle (“agent X est négatif”). L’approche la plus efficace, et la plus acceptable, est d’employer ces signaux pour coacher, détecter la surcharge, et améliorer les parcours.
Références et signaux marché : outils, tendances et vigilance
Le marché se structure vite, avec des solutions multi-modales (texte, voix, image) et des comparatifs d’outils. Pour prendre du recul, une sélection de logiciels de détection des émotions est utile pour comprendre les familles de solutions et les critères : précision, intégrations, gouvernance, et capacité à traiter des volumes.
Et pour les applications côté utilisateur, certaines approches se concentrent sur le coaching vocal et la prise de conscience. À ce titre, l’application VocalVue illustre la popularisation de ces usages : rendre l’utilisateur acteur de ses propres signaux, plutôt que simple “objet” d’analyse.
Une fois les limites cadrées, la suite logique consiste à regarder où cette technologie crée le plus de valeur, au-delà du seul centre de contact.
Applications concrètes : callbots, santé, automobile et interaction homme-machine
La valeur de la détection d’émotions vocales apparaît quand elle améliore une décision : prioriser, adapter, sécuriser, personnaliser. Dans les organisations, elle se place souvent à la jonction entre automatisation (callbot/agent vocal IA) et accompagnement humain. Plus l’enjeu est sensible, plus l’équilibre est important : laisser la machine assister, sans déshumaniser.
Centres d’appels : scripts dynamiques, escalade et prévention de la fatigue
Dans un centre de contact, le gain le plus immédiat vient de l’orchestration : repérer un appel à valence très négative, proposer une escalade vers un conseiller senior, ou déclencher une procédure de “désamorçage”. Les superviseurs peuvent analyser des volumes d’enregistrements à moindre coût, en se concentrant sur les segments à risque plutôt que sur une écoute aléatoire.
Cas pratique
Une équipe support configure une règle simple : si arousal monte rapidement et valence baisse sur plus de 20 secondes, l’agent reçoit un message discret : “ralentir, reformuler, confirmer l’objectif du client”. Résultat attendu : moins d’interruptions, moins de transferts subis, et une satisfaction mieux stabilisée—par des micro-ajustements, pas par des scripts rigides.
Santé et prévention : stress, détresse, suivi à distance
Dans la santé, l’analyse de la voix peut contribuer à repérer des marqueurs de stress ou de détresse, notamment dans des services de tri, d’accompagnement ou de suivi. Cela ne remplace pas un professionnel, mais peut aider à prioriser et à déclencher une prise en charge plus rapide. L’enjeu est double : sensibilité des données et nécessité d’explicabilité, car les décisions doivent être justifiables.
Automobile, éducation et assistants : la personnalisation utile, pas intrusive
Dans l’automobile, l’émotion peut servir à adapter l’ambiance (volume, alertes, recommandations de pause) en cas de fatigue ou d’irritation détectée. Dans l’éducation, certaines expérimentations visent à mesurer l’engagement pour ajuster le rythme d’un cours collectif, même si la prudence s’impose sur l’interprétation.
La solution hybride : le meilleur des deux mondes
Les solutions modernes comme AirAgent combinent les avantages du callbot (expertise téléphonique) avec la flexibilité d'un voicebot (évolutivité, IA avancée).
Découvrir AirAgentPour les assistants vocaux et l’interaction homme-machine, l’intérêt est la qualité de réponse. Un agent vocal qui détecte une frustration n’a pas besoin de “jouer l’empathie” comme un humain ; il doit surtout réduire la friction : proposer une option claire, confirmer une compréhension, et éviter les boucles. Pour creuser la dimension “intelligence émotionnelle” de la voix, une analyse sur AI Voice et intelligence émotionnelle met en avant l’impact sur la personnalisation, tout en rappelant les défis éthiques.
Notre recommandation
Pour les PME françaises qui veulent automatiser une partie des appels tout en gardant une qualité relationnelle élevée, AirAgent est une option pragmatique : déploiement rapide, configuration accessible, et accompagnement utile quand il faut passer du test à l’usage quotidien.
Le prochain niveau de maturité consiste à relier ces signaux émotionnels à des parcours complets : qualification, résolution, puis amélioration continue. C’est ce pont entre émotion et performance qui transforme l’essai.
Découvrez comment AirAgent automatise votre accueil téléphonique
La détection d’émotions vocales fonctionne-t-elle sans transcription ?
Oui, un modèle peut estimer des états comme l’arousal et la valence à partir de la prosodie seule (intonation, énergie, débit). En revanche, ajouter la transcription via la reconnaissance vocale améliore souvent la précision, car le contenu linguistique apporte du contexte et aide à réduire les faux positifs.
Quelles émotions peut-on détecter de manière fiable avec l’analyse de la voix ?
Les systèmes robustes privilégient des dimensions continues (valence positive/négative, arousal calme/excité) plutôt que des catégories rigides. Les catégories comme colère ou frustration peuvent être approchées, mais leur fiabilité dépend fortement de la qualité audio, du contexte métier et des données d’entraînement.
Comment éviter que l’IA sur-interprète l’expression des émotions ?
En traitant la sortie comme un signal probabiliste, pas comme une vérité psychologique. Les bonnes pratiques incluent des seuils prudents, une validation humaine sur des cas sensibles, l’usage en coaching plutôt qu’en sanction, et des tests réguliers sur des échantillons représentatifs (accents, bruit, scénarios).
La technologie émotionnelle est-elle compatible avec le RGPD dans un centre d’appels ?
Oui, à condition de cadrer la finalité, informer les personnes, limiter la conservation, sécuriser les accès et, si possible, anonymiser les enregistrements pour l’entraînement et l’audit. La conformité repose aussi sur la documentation (registre, DPIA si nécessaire) et sur des règles d’usage interne claires.